Answer the following questions about lecture material from week 1.
Suppose memory contains the following 8-bit bytes at the following addresses (each written in hexadecimal):
address
value
...
...
0x0FD
0x11
0x0FE
0x22
0x0FF
0x33
0x100
0x44
0x101
0x55
0x102
0x66
0x103
0x77
0x104
0x88
0x105
0x99
0x106
0x00
0x107
0xA0
0x108
0xAB
0x109
0xBA
0x10A
0xC0
0x10B
0xD0
...
...
Question 1 (2 pt; mean 1.4) (see above)
In little-endian, reading a four-byte (32-bit) value from address 0x105 yields what value?
Write your answer as a hexadecimal number. If not enough information is given write "unknown".
Answer:
Key: /(0[xX])?0*[aA][bB][aA]00099|2879389849/
0xaba00099 constructed from 0x99, 0x00, 0x0A, 0xAB at addresses 0x105 through 0x109 inclusive. Relucantly accepted if you decided that it should be written with the least significant hexadecimal nibble left-most (99000ABA), but it was our intention that "little-endian" just applied to how the value was read from memory.
Question 2 (2 pt; mean 1.77) (see above)
With the above memory layout, running movb 0x104, %al what will the value of the 8-bit register %al be?
Write your answer as a hexadecimal number. If not enough information is given write "unknown".
When run with the above memory layout, what will the resulting value of the 32-bit register %eax be?
Write your answer as a hexadecimal number. If not enough information is given write "unknown".
0xBAABA000; reads from 0x100 + 4 + 1 * 2 = 0x106; constructed from 0x00, 0xA0, 0xAB, 0xBA
Question 4 (3 pt; mean 2.87)
Consider the following AT&T syntax assembly:
addq %rbx, %rbx
addq %rax, %rbx
movq (%rbx), %rax
Which of the following assembly snippets will result in the same
final value of %rax? (Ignore changes to the value of %rbx.) Select all that apply.
Question 5 (2 pt; mean 1.59)
Suppose the assembly label array is defined to be a constant 5-byte array as follows:
array:
.byte 3
.byte 4
.byte 5
.byte 6
.byte 7
and the linker chooses to locate this array at address 0x10000.
(Each .byte directive specifies the value of one byte of memory.)
Then, if we run the assembly snippet:
movq $1, %rax
addq $array, %rax
movb 1(%rax), %bl
What would the value of 8-bit register %bl be afterwards? You may assume memory around array is not
modified before this snippet is run.
Write your answer as a hexadecimal number. If not enough information is given write "unknown".
Answer:
Key: /(0[xX])?0*5/
after movq, %rax = 1; after addq, %rax = 0x10001; movb computes the address 0x10001 + 1 = 0x10002, which contains 5
quiz for week 2
Answer the following questions about lecture material from week 2.
Question 1 (2 pt; mean 1.73)
Consider the following C function:
long foo(long a, long b) {
return a + b;
}
Which of the following are correct translations (but perhaps unnecessairily complex)
of this function to AT&T syntax assembly (using the Linux x86-64 calling convention)?
Select all that apply.
Consider the following C function:
long example(long a, long b) {
while (a > b) { a = a - b; }
return a;
}
Question 2 (2 pt; mean 1.63) (see above)
This function can be converted to x86-64 assembly (following Linux's x86-64 calling convention)
like the following:
example:
cmpq %rsi, %rdi
____ L_done
subq %rsi, %rdi
jmp example
L_done:
movq %rdi, %rax
ret
What instruction goes in the blank (in the second instruction of the function before L_done)?
rdi (a) - rsi (b) <= 0 --> a <= b --> escape loop
Question 3 (2 pt; mean 1.58) (see above)
Assuming the assembly translation from the previous question is used,
after this function returns, what will the value of the zero flag (ZF) will be?
the last instruction run that sets ZF is cmpq, which is comparing what will become the return value to the original argument b; if the subtraction done by the compare reuslts in zero, that means the two values are equal
Suppose we assemble the following into an object file:
.data
.global array
array:
.byte 1
.byte 2
.byte 3
.byte 4
.text
.global bar
bar:
cmpq $0, %rdi
je end_bar
movq $array, %rdi
call print_array
end_bar:
movq $array, %rax
ret
Question 4 (2 pt; mean 1.72) (see above)
The corresponding object file's relocations table will reference which of the following
(either by name or by identifying the location of the corresponding label)? Select all that apply.
required for movq $array, %rdi instruction
appears in symbol table, but not used by any instruction
required for call print_array instruction
Question 5 (2 pt; mean 1.09) (see above)
When using the resulting object file to produce an executable (using the static (non-dynamic) linking scheme
we discussed in lecture), the linker will _______.
Select all that apply.
not referenced by any other instruction, no label permitting it to be located. Note that this question asks about the memory address of the call instruction, not about the memory adddress of print_array
Consider the following C function:
int *quux(int *p) {
int *r;
r = p + 2;
*r += 4;
return r;
}
Question 6 (2 pt; mean 1.56) (see above)
Suppose the function quux is run on a Linux x86-64 system where:
ints are 4 bytes,
p points to the first element of an array of 400 ints located at address 0x10000
each of the 100 ints in the array initially has the value 7
What will the value of the pointerr be just before the quux returns?
Write your answer as a hexadecimal number.
(Be sure to give the value of the pointer and not the value it points to.)
Answer:
Key: /(?:0[xX])?0*10008/
2 advances by two ints -- 4 bytes each; initial value of the array is irrelevant, but I did make a mistake in being inconsistent about the size of the array.
quiz for week 3
Answer the following questions about lecture material from week 3
Consider the following C function:
long example(long a) {
long last_a = a;
while (a != (a >> 40)) {
last_a = a;
a = a >> 40;
}
return last_a;
}
Assume >> on integers is implemented using an arithmetic shift (copies the sign bit for leftmost bits of
result) and longs are 64 bits, represented using two's complement.
Question 1 (2 pt; mean 1.72) (see above)
The value of example(1) is 1.
Besides 1, what is another value K such that example(K) is 1? (There are several possible answers.)
Write your answer as a base-10 number.
between 1099511627776 (2^40) and 2199023255551 (2^41-1). At some point, last_a was 1, then a became 0 and 0 != 0 >> 40, terminating the while loop. Before this happened, a was some number such that a >> 40 was 1. Since >> 40 is equivalent to dividing by 2 to the 40th, this is any number where dividing by 2 to the 40th would round down to 1.
Question 2 (2 pt; mean 1.22) (see above)
How many distinct return values can the above example function have? Write your answer as a base-10 number.
Answer:
Key: /2199023255552/
-2^40 through 2^40-1, inclusive; three-fourths credit given for half that (forgot negative) or off-by-one; X == X >> 40 only if X is 0 (all zeroes) or -1 (all ones). Y >> 40 is 0 or -1 only if bits 40-63 of Y are all 0s or all 1s. Alternate, Y >> 40 is only 0 or -1 if dividing Y by to 2 to the 40th power would round down to 0 or -1.
Question 3 (2.5 pt; mean 2.27)
If x and y are 32-bit signed ints
with values between -1000000 and 1000000
on a system that uses two's complement, which of the following C expressions are always true? Select all that apply.
was originally miskeyed; should be always true
was originally miskeyed and this explanation was originally wrong; countrexample: x = 0xF000, y = 0x0 (x & 0xFFF) >> 8 is 0, so the left-hand side is 0; but ((x >> 8) ^ y) is 0xF0, so the right hand side is 0xF0.
Question 4 (2 pt; mean 1.69)
Which of the following C expressions will, given an unsigned integer x, return the least significant
4 bits of the integer with its bits reversed. For example, if x in binary was 11001000001101,
the result would be (in binary) 1011 (the reverse of 1101).
Select all that apply.
Question 5 (2.5 pt; mean 2.22)
Which of the following are examples of properties of an instruction set architecture (ISA) as
opposed to properties of a particular microarchitecture?
quiz for week 4
Answer the following questions about lecture material from week 4.
Question 1 (2 pt; mean 1.66)
Which of the following are likely attributes of processors following the RISC (reduced instruction set computer)
design philosophy when compared to processors following the CISC (complex instruction set computer) design
philosophy? Select all that apply.
dropped, because we neglected to discuss what a register file is; RISC designs typically want to increase the number of registers versus a typical CISC to make up for not being able to access memory during most instructions
processor implements fewer instructions, though programs will need more instructions
implies variable length instructions
Question 2 (2 pt; mean 1.9)
Which of the following are valid Y86-64 code? Select all that apply.
no scale-based memory addressing
no 32-bit registers
Question 3 (2 pt; mean 1.42)
Consider the following Y86-64 machine code, written as a sequence of bytes in hexadecimal:
During cycle 10, Y_foo has the value 500 and Y_bar has the value 300.
What is the value of Y_foo during cycle 12? (Write your answer as a base-10 number, like 123.)
Assume that cycles are seperated by a rising edge of the clock signal.
Answer:
Key: 600
cycle 11: Y_foo = (500+300) = 800; Y_bar = (300-500) = -200; cycle 12: Y_foo = (800-200) = 600; was originally miskeyed (because I swapped values when subtracting)
Question 6 (2 pt; mean 1.67)
Using the kind of registers we described in lecture and in section 4.2.5 of our textbook,
suppose a register's output is 42 and its
value input is also 42 and the clock signal is high. Then the following happens in this order:
the clock signal falls (becoming low)
the register's value input changes to 44
the register's value input changes to 45
the clock signal rises (becoming high again)
the register's value input changes to 46
the clock signal falls (becoming low)
the register's value input changes to 47
What will the value of the register's output be after this occurs? If not enough information is given
to answer write unknown and explain in the comment field.
Answer:
Key: 45
quiz for week 5
Answer the following questions about lecture material from week 5.
Question 1 (2 pt; mean 1.84)
Consider the following HCLRS code snippet:
wire x : 64;
wire y : 64;
x = [
y == 4 : 4;
(y & 1) == 0 : 3;
y > 10 : 2;
1 : 1;
];
If y is 100 what is the value of x?
Answer:
Key: 3
Question 2 (2 pt; mean 1.54)
Using the instruction memory design we discussed in lecture designed for use in implementing
the Y86-64 instruction set, the size of the output of the instruction memory ____.
If this were part of an HCLRS processor which does not have any other code using the register file
inputs and outputs, then
Rather than having call and ret instructions that push and pop values from the stack,
many instruction sets instead store the return adddress in a register (which, if necessary, programs
can save on the stack).
For example, RISC V provides a jal REGISTER, TARGET_LABEL ("jump and link") instruction to replace
the functionality of call and a jr REGISTER ("jump to register") to replace the functionality
of return. Like call, jal REGSITER, TARGET_LABEL stores the return address and then jumps to
TARGET_LABEL, but it stores it in REGISTER, rather than on the stack. (If necessary, the
function can use another instruction to push the return address onto the stack.)
jr REGISTER takes a value from a register and sets the PC to the value.
Question 4 (2 pt; mean 1.24) (see above)
Suppose we added the jal instruction described above to the single-cycle Y86-64 procesor design we
described in lecture (and which is described in our textbook).
(By "single-cycle processor", we mean a processor that executes one cycle per reigster.)
To avoid adding inputs to MUXes or additional MUXes (or similar circuitry) to
control the 4-bit register number inputs to the register file
(reg_srcA, reg_srcB, reg_dstE, and reg_dstM in HCLRS), which of
the below encodings would be best?
(In each of the encodings, values of each byte are provided with most significant bits written first (left-most).)
register number we need to write in a different location in instruction memory output than any other instruction that writes registers
can reuse MUX option from mov or add instruction
register number we need to write in a different location in instruction memory output than any other instruction that writes registers
can't implement this instruction since no destination register
Question 5 (2 pt; mean 1.33) (see above)
Suppose we added the jal instruction descrbied above to the single-cycle processor design we described in lecture
(and which is described in our textbook).
While this instruction is executing the input to the PC register would most likely be equal to
constant from the instruction specifies the address of the next instruction to run
Question 6 (2 pt; mean 1.59)
In the single-cycle Y86-64 processor design we discussed in lecture, which of the following
operations may overlap in time with the addition of registers' values for an add instruction?
Select all that apply.
independent of add, circuit can act at same time
not executing an instruction that should do this at all
won't be done until addition completes
not triggered by any particular part of clock signal but has to be done before the addition can actually happen
quiz for week 6
Answer the following questions about lecture material and lab from week 6.
Question 1 (2 pt; mean 1.56)
In lab to implement condition codes, we suggested declaring condition code registers using
register cC {
SF:1 = 0;
ZF:1 = 1;
}
and then using
stall_C = (icode != OPQ);
to keep the condition code registers
from changing when the instruction was not an OPq instruction. We noted that, in HCLRS,
"Register banks like cC have a special input stall_C which, if 1, causes the
registers to ignore inputs and keep their current value." (Each register bank has its own
stall signal, this one is stall_C, since the condition code registers were declared using
register cC.)
If register banks did not provide this stall signal, we could have implemented the functionality
using a case expression (MUX) when setting c_SF and c_ZF. What would the corresponding code
for setting c_ZF look like?
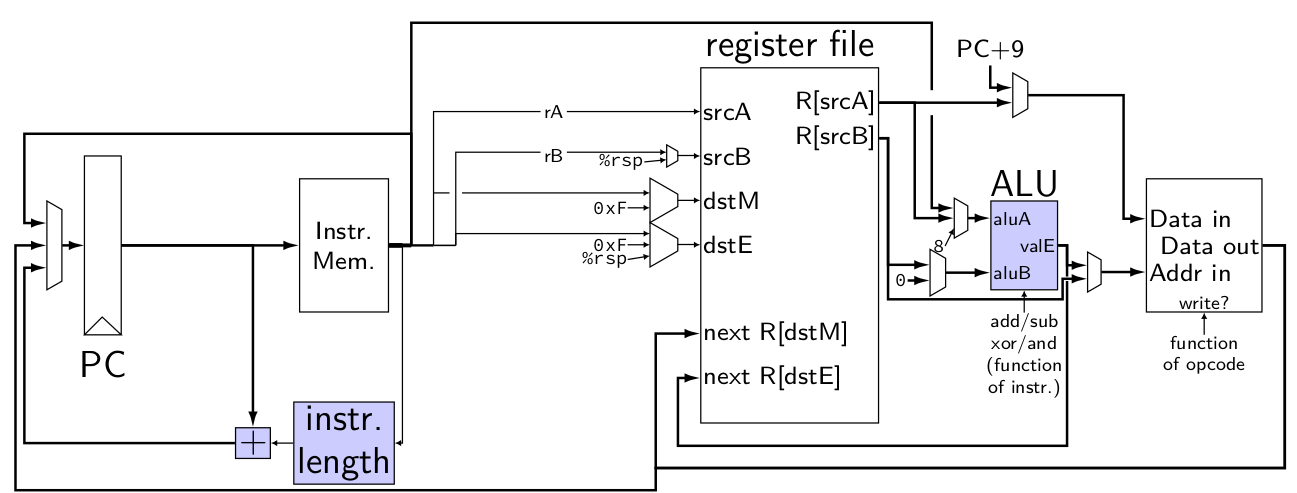
Consider the following diagram of the single-cycle processor data path from lecture:
Note that in this version of the processor design, the second input to the ALU
(which our textbook calls aluB) is 0 or the second output of the register
file (reg_outputB in HCL).
Suppose we wanted to implement a new instruction ixorq on this processor, which
would xor a register's value with a constant and store the result in a register. For example
ixorq $0x1234, %rax
would take the value of %rax, xor it with 0x1234 and store the result in %rax. In
machine code, the instruction would have the same layout (placement of fields like icode
and rA and valC) as irmovq.
Question 2 (2 pt; mean 1.61) (see above)
When this ixorq instruction is executing the MUX that controls the dstM regsiter file
input should ____.
the place where the rA field is will always be REG_NONE already, so the selection shouldn't matter
Question 3 (2 pt; mean 1.75) (see above)
When this ixorq instruction is executing the MUX that controls the aluB ALU input
should ____.
Question 4 (2 pt; mean 1.85)
Consider a three-stage pipelined processor
The operations of the stages of this processor, including register delays for
any required pipeline registers, take:
200 ps (first stage)
250 ps (second stage)
300 ps (third stage)
What is the best possible cycle time of this processor? Write your answer as a base-10 number of picoseconds.
Answer:
Key: 300
Question 5 (2 pt; mean 1.41)
Consider a three-stage pipelined processor has a cycle time of 500 picoseconds.
Suppose this processor runs 5 instructions in the following order: A (completes first), B, C, D, and E (completes last).
What is the time between when the instruction A starts its
first stage and when instruction E starts its third stage? If multiple amounts of time
are possible, write the minimum time.
Write your answer as a base-10 number of picoseconds.
Answer:
Key: 3000
Question 6 (2 pt; mean 1.58)
Suppose a processor designer took a three-stage pipelined processor design with a cycle time of
800 ps and turned it into a six-stage processor pipelined design that implemented the same ISA.
Both the three-stage and six-stage processors were designed to achieve about the best
cycle times possible (despite the constraints that lead to diminishing returns as one tries to add
pipeline stages to a processor).
Which of the following would be the most likely cycle time for the six-stage processor design?
could achieve this delay by three "empty" extra stages
assumes register delay is truly negligible
better than ideal
quiz for week 7
Answer the following questions about lecture material from week 7.
Question 1 (2 pt; mean 1.6)
Suppose we have a six-stage pipelined processor with 500 ps cycle time.
Running a particular benchmark program which executes 1 billion (10 to the 9th power) instructions in a simulator, we determine that 5% of its instructions require exactly one cycle of stalling and 10% require exactly two cycles of stalling and no instructions would require more than two cycles of stalling.
(For the purposes of this question, a cycle of stalling means one bubble (hardware-generated nop) inserted in the pipeline rather than advancing an instruction. Assume we attribute each stall to exactly one instruction.)
Assume these stalls are the only reasons why the processor would not complete one program instruction
every cycle.
To the nearest millisecond, how long (in milliseconds) will the benchmark program take to run? Write your answer
as a base-10 number of milliseconds.
Answer:
Key: 625
For the following two questions, consider executing the following assembly snippet:
Suppose the assembly snippet is executing on the five-stage pipelined processor we described in lecture,
but instead of using forwarding, it uses only stalling to resolve data hazards (and no forwarding).
If the first addq instruction is fetched in cycle 0, then during what cycle will the final addq
instruction run its writeback stage?
Answer:
Key: 16
without stalling: first addq does writeback in cycle 4, so last addq does writeback in 4 + 4 = 8. Add in stalling: 3 cycles before subq to wait for first addq; 2 cycles before rrmovq to wait for subq; 3 cycles before final addq to wait for rrmovq
Question 3 (3 pt; mean 2.67) (see above)
Suppose the assembly snippet is executing on the five-stage pipelined processor we described in lecture that:
uses forwarding to resolve data hazards to the extent possible without dramatically increasing the cycle time
Which of the following forwarding operations must occur
to avoid the most stalling possible? Select all that apply.
not written by subq
value is not used by rrmovq, so value is not necessary (though sending it would be harmless)
overwritten by rrmovq
For the following question, consider executing the following assembly snippet:
Suppose the assembly snippet above were executed on a six-stage pipelined processor with the following stages:
Fetch
Decode
Execute
Memory 1
Memory 2
Writeback
This processor acts like the processor we discussed in lecture and implements all forwarding
possible (that wouldn't dramatically increase cycle times).
For the purpose of forwarding, when the stages are not split, we generally assume:
a value needed for a computation or storage access can only be used by a stage if it's computed or retrieved in the previous cycle
Similarly, for the split memory stages, assume:
for instructions that read from the data memory, the address to read must be computed
in the cycle before the Memory 1 stage runs, and
the result of any memory read is only available to be used (e.g. after being forwarded) by other instructions in
the cycle after the Memory 2 stage runs
Given this processor, if the addq performs its fetch stage during cycle 0, then
during what cycle number will the rmmovq instruction finish its writeback stage?
Answer:
Key: 10
also gave credit for 11, since a relatively common interpretation of "result is only available to be used ... after the Memory 2 stage runs" was that you couldn't forward it during Memory 2. (My intention was that "e.g. after being forwarded" would suggest that forwarding the value only didn't count as a "use" for this purpose, but I see that was less clear than I thought...)
Question 5 (2.5 pt; mean 2.18)
Consider the following assembly snippet:
(where ... represents irrelevant
instructions):
addq %rax, %rcx
subq %rcx, %rdx
je foo
xorq %rcx, %rdx
...
...
...
foo:
irmovq $10, %rax /* A */
irmovq $20, %rbx /* B */
...
where the je is not taken.
Suppose that we are executing the assembly snippet on
a five-stage pipelined processor based on the design in lecture that:
uses forwarding to resolve data hazards to the extent possible without substantially increasing the cycle time, and
speculates that all conditional jumps will be taken, like we described in lecture, so the instructions labeled A and B will be fetched in the two cycles after the je is fetched and then squashed (discarded)
when a conditional jump is not taken like the processor guessed, fetches the corrected instruction during the memory stage of the conditional jump instruction (the cycle after determining what address to fetch in the conditional jump's execute stage)
Which of the following is true about what happens when the above assembly executes? Select all that apply.
xorq in fetch --> je in memory --> subq in writeback
quiz for week 8
Answer the following questions about lecture material from week 8.
Suppose we are implementing a five-stage processor with a similar design to the one discussed in lecture,
but sometimes we need to stall for one cycle because the output of the data memory needs an extra
cycle to be retrieved.
Suppose the instruction triggering the stall is in the memory stage during cycle number 0,
and needs to stay in the memory stage until cycle number 1 to complete the memory read.
(For the purposes of this question, we say an instruction is in a stage when its values
are being output from the corresponding pipeline registers.)
Complete in the following statements about how the pipeline registers should behave.
Question 1 (0.5 pt; mean 0.35) (see above)
During cycle number 1, the pipeline registers between fetch and decode
Question 2 (0.5 pt; mean 0.31) (see above)
During cycle number 1, the pipeline registers between decode and execute
Question 3 (0.5 pt; mean 0.31) (see above)
During cycle number 1, the pipeline registers between execute and memory
Question 4 (0.5 pt; mean 0.27) (see above)
During cycle number 1, the pipeline registers between memory and writeback
For the following two questions,
consider a 4-block direct-mapped cache with 4 byte cache blocks.
For each of the following two questions, assume the cache's contents are as follows:
index (in base 2)
valid bit
tag (in base 2)
data (hexadecimal, list of bytes, lowest address left-most)
00
1
001001
23 56 78 9A
01
1
001001
AA BB CC DD
10
1
000011
01 02 03 04
11
0
000000
00 00 00 00
For the following two questions,
write down what the result of reading one byte from the specified addresses will be
(assuming the cache has the contents listed above when the access occurs):
if the result will be a cache hit, write the value that will be read in hexadecimal (with or without a leading 0x)
if the result will be a cache miss, write the word miss.
(Note that addresses may have leading zeroes which are not written.)
Question 5 (1 pt; mean 0.94) (see above)
0x91
Answer:
Key: 56
Question 6 (1 pt; mean 0.94) (see above)
0x3B
Answer:
Key: /0?4/
For the following two questions,
consider a 4-block 2-way set associtiative-mapped cache with 4 byte cache blocks whose contents are as follows:
index (in base 2)
valid bit (way 0)
tag (in base 2) (way 0)
data (hexadecimal, list of bytes, lowest address left-most) (way 0)
valid bit (way 1)
tag (way 1)
data (way 1)
0
1
0010010
23 56 78 9A
1
0010011
AA BB CC DD
1
1
0000110
01 02 03 04
1
0000011
71 82 93 F3
For the following two questions,
write down what the result of reading one byte from each of the specified address will be
(assuming the cache has the contents listed above when the access occurs):
if the result will be a cache hit, write the value that will be read in hexadecimal (with or without a leading 0x)
if the result will be a cache miss, write the word miss.
(Note that addresses may have leading zeroes which are not written.)
Question 7 (1 pt; mean 0.93) (see above)
0x91
Answer:
Key: 56
Question 8 (1 pt; mean 0.96) (see above)
0x3B
Answer:
Key: miss
Question 9 (2 pt; mean 1.64)
Consider a direct-mapped cache which
contains 256KB of data (1KB = 1024 bytes) and uses 256 byte blocks.
When there is a cache miss for address 0x12345, this cache will copy an entire
256-byte block from memory into the cache. What is the lowest address of
a byte in this block? (Write your answer in hexadecimal.)
Answer:
Key: /(?:0[xX])?0*12300/
quiz for week 9
Answer the following questions about lecture material from week 9.
Question 1 (2 pt; mean 1.73)
Consider a 64KB direct-mapped cache with 32 byte blocks. (1KB = 1024 bytes)
In this cache, the byte at address 0x12345 would (if present in the cache) be stored in the same set as the byte at address ____ would be stored (if present in the cache).
Select all that apply.
Question 2 (2 pt; mean 1.7)
Consider a 8KB 2-way set associtiave cache with an LRU replacement policy and 64-byte blocks. (1KB = 1024 bytes.)
Suppose the cache is initially empty (all valid bits set to 0), then the program
acceses 1 byte from each of the following addresses in
the following order:
0x10005
0x40000
0x12400
0x10001
0x33320
Immediately after the accesses described above, give an example of an address which, if
read using this cache, would cause something to be evicted from the cache:
(key does not match some correct answers (and may incidentally match some incorrect ones); we'll go through and manually grade these over the next week)
Consider a two-set direct-mapped cache with 8B blocks and a write-allocate and writeback policy.
Suppose the cache is initially empty (all blocks invalid) and we perform the following accesses of single bytes:
read from 0x104
write to 0x101
write to 0x102
write to 0x108
read from 0x109
read from 0x10f
read from 0x110
read from 0x118
write to 0x119
Question 3 (1 pt; mean 0.87) (see above)
Will the read from 0x109 be a hit?
Question 4 (1 pt; mean 0.91) (see above)
Will the read from 0x10f be a hit?
Question 5 (2 pt; mean 1.69) (see above)
Which of these reads from the access pattern above will trigger a write to memory (or the next level of cache)? Select all that apply
Question 6 (2 pt; mean 1.4)
Suppose we have a system with:
a 2-set direct-mapped cache with 8 byte cache blocks
4-byte ints (so each cache block can store 2 ints)
array[0] is assigned an address at the beginning of a cache block
the assembly the compiler generates for the above code does not reorder or omit data cache accesses
only accesses to array use the data cache, and
the cache is initially empty
how many data cache misses should we expect?
(Note that unlike the examples in lecture,
the 9 accesses here are not evenly distributed across cache sets.)
Answer:
Key: 6
quiz for week 10
Answer the following questions about lecture material from week 10.
Consider the following 2 versions of C code:
/* Version 1 */
for (int i = 0; i < N; ++i) {
for (int j = i; j < N; ++j) {
C[j] += A[i*N+j] * B[j];
}
}
/* Version 2 */
for (int j = 0; j < N; ++j) {
for (int i = j; i < N; ++i) {
C[j] += A[i*N+j] * B[j];
}
}
Question 1 (1 pt; mean 0.95) (see above)
Which version has better temporal locality in accesses to C?
Question 2 (1 pt; mean 0.95) (see above)
Which version has better spatial locality in accesses to A?
Question 3 (2 pt; mean 1.66) (see above)
If N is 100000 and cache blocks can hold 8 elements of the array B,
then we would expect approximately _____ cache misses for the accesses to B
when running version 1 of the code above.
(Choose the closest answer.)
Assume the cache is not large enough to hold 50000 elements of B (or A or C).
In lecture, we discussed how an out-of-order processor may perform
register renaming where it converts instructions from
using architectural registers (the ones that appear in assembly)
to physical registers (used internally in the processsor). When doing this,
the processor ensures that each version of an architectural register's
value uses a different physical register, which aids in resolving hazards.
After an out-of-order processor performs register renaming
on the above instructions as discussed in lecture, which of the following statements
about the physical registers used by the renamed
versions of the above instructions will be true?
quiz for week 11
Answer the following questions about lecture material from week 11.
Question 1 (2 pt; mean 1.73)
Suppose an out-of-order processor has two execution units (that matter for this questions):
a 1-cycle adder (that can perform one add per cycle)
a 3-cycle pipelined multiplier (that can start one multiply per cycle, but finishes it two cycle later)
Suppose on this processor
the results of an addition or multiply can be used to start another addition or multiply
in the cycle after the first addition or multiply completes.
Consider the following C snippet:
a = b + c;
d = e * f;
h = a + d;
i = a * d;
With the processor described above,
what's the fastest time (in cycles) the above C snippet can execute?
(Do not attempt to count for time doing instruction fetching, register renaming, etc. — just
the time to finish the actual computation.)
Answer:
Key: 6
Question 2 (2.5 pt; mean 2.24)
In lecture, we discussed the use of multiple accumulators to improve performance in addition to simple
loop unrolling. Consider the following pair of unrolled loops with and without use of multiple
accumulators:
Whether this transformation would be helpful depends on the execution units the processor has.
Suppose
the performance of the execution units that perform the multiplications
(represented by a * operations
in the C code above) is what determines the performance of the loop overall.
To make it easier to reason about performance, assume
the execution units that perform these multiplications are never involved in any of the address
or index calculations needed by the loop above (so one only needs to consider how the
multiplication instructions are dispatched and executed).
Given which configuration(s) of execution units to perform the multiplications
could the loop's performance benefit
from the multiple accumulators optimization shown above?
Select all that apply.
Question 3 (2 pt; mean 1.62)
Which of the following optimizations are likely to significantly decrease the number of times an instruction
that accesses the data cache runs? Select all that apply.
more calls to strlen() and each call to strlen() needs to read the loop
mov instruction for 256-bit register moves more at a time
loop index management probably doesn't use the data cache, and the loop body runs the same instructions as before
(accepted either answer) generally doesn't, but might allow compiler to keep something in a register that it couldn't otherwise (if it's now reused in the innermost loop) if it can show that alaising isn't a concern
Question 4 (2 pt; mean 1.54)
Consider the following two C functions:
void all_pairs_products1(int N, int *A, int *result) {
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
result[i * N + j] = A[i] * A[j];
}
}
}
void all_pairs_products2(int N, int *A, int *result) {
for (int j = 0; j < N; ++j) {
for (int i = 0; i < N; ++i) {
result[i * N + j] = A[i] * A[j];
}
}
}
(The two functions differ in their loop orders.)
A compiler cannot generate identical for these two functions because in cases where
A and result are pointers that refer to the same data (a problem we called "aliasing"),
they can write different answers to the result array.
Which of the following are examples of calls to all_pairs_products1 which could result
in different values in the array array than if the same call were made to all_pairs_products2 instead?
Select all that apply.
originally keyed incorrectly; only elements 0-1023 of A are used, so no overlap possible
originally keyed incorrectly; will end up reading things written into result in future iterations in both cases, but with different orderings of whether things that written are read
quiz for week 12
Answer the following questions about lecture material from week 12.
Question 1 (2 pt; mean 1.6)
In lecture we discussed vector instructions (also known as SIMD instructions) where a single
instruction can perform an operation on every pair of values in two vectors, which are
typically fixed-sized array stored in registers.
Using vector instructions similar to those used in the lab,
which of the following code snippets is simplest to transform into a version
that makes effective use of vector instructions?
/* loop A */
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
A[j*N + i] += A[i*N + j];
}
}
/* loop B */
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
A[i*N + j] += B[j] * C[(i+1)*N + j];
}
}
/* loop C */
for (int i = 2; i < N; ++i) {
A[i] *= (A[i-1] + A[i-2]);
}
(Assume A, B, and C are independent arrays.)
need to have a good way to load/store non-contiguous values from A (separated by N)
difficult to compute A[i] before having computed A[i-1], but we'd want to compute both of them at the same time with vector instructions
Question 2 (2 pt; mean 1.75)
Suppose a program A makes a system call requesting to "sleep" for 2 seconds. During those 2 seconds
the operating system runs a program B, then it switches back to program A.
When the operating system later switches back to program A, the first instruction it runs is most likely:
Question 3 (2 pt; mean 1.51)
In lecture, we discussed the idea of an exception table, which is used as part of handling exceptions.
Which of the following statements about the exception table are true?
to find the address of the exception handler
the hardware saves this, but not in this table
the address of the exception handler
no, because then program's can override the OS's choices about, e.g., how long they should be allowed to run
Question 4 (2 pt; mean 1.31)
Suppose a system has 15-bit virtual addresses, 13-bit physical addresses, and page tables with a total of 32
entries.
What is the size of pages on this system (in bytes)?
Answer:
Key: 1024
For the following questions,
consider a system with 20-bit virtual addresses where virtual addresses are divided into a
16-bit page offset and a 4-bit virtual page number. (For example,
virtual address 0x12345 has virtual page number 0x1 and page offset 0x2345.)
Suppose the contents of the page table of this system are:
virtual page number
valid
physical page number
0x0
0
0x00
0x1
1
0x15
0x2
1
0x14
0x3
1
0x20
0x4
1
0x05
0x5
1
0x06
0x6
1
0x09
0x7
0
0x00
0x8
0
0x00
0x9
1
0x13
0xA
1
0x14
0xB
1
0x30
0xC
1
0x31
0xD
1
0x32
0xE
1
0x33
0xF
1
0x34
Question 5 (1 pt; mean 0.82) (see above)
Based on the page table above,
when accessing the virtual address 0x30001, what physical address will be accessed?
Write your answer as a hexadecimal number. If a fault (an exception) would occur, write
"fault".
Answer:
Key: /(?:0[xX])?0*200001/
Question 6 (1 pt; mean 0.81) (see above)
Based on the page table above,
when accessing the virtual address 0x5467F, what physical address will be accessed?
Write your answer as a hexadecimal number. If a fault (an exception) would occur, write
"fault".
Answer:
Key: /(?:0[xX])?0*6467F/
quiz for week 13
Answer the following questions about lecture material from week 13.
Suppose a system has:
20-bit virtual addresses
1024 byte pages
24-bit physical addresses
4 byte page table enties
a page table base pointer set to physical (byte) address 0x1000
a single-level page table structure
Question 1 (2 pt; mean 1.03) (see above)
Based on the above information,
what is the address at which the page table entry for the virtual address 0x1000 is stored?
(Note that page table entries are larger than one byte.)
Write your answer as a hexadecimal number.
Answer:
Key: /(?:0[Xx])?1010/
Question 2 (2 pt; mean 1.26) (see above)
How large are page tables on this system (in bytes)?
Answer:
Key: 4096
Suppose a system has:
42-bit virtual addresses (maximum value 0x3FF FFFF FFFF), with a 30-bit virtual page number and a 12-bit page offset
30-bit physical addresses (maximum value 0x3FFF FFFF), with an 18-bit physical page number and a 12-bit page offset
three-level page tables, where 10 bits of the virtual page number are used for a lookup at each level
page table entries are four bytes
Question 3 (2 pt; mean 1.14) (see above)
When looking up the virtual address 0x012 3456 789A, if the page
table base pointer contains the physical byte address 0x44 000,
then what is the physical address of the first-level page table entry for 0x012 3456 789A?
(Note that page table entries are larger than one byte.)
Write your answer as a hexadecimal number.
Answer:
Key: /(?:0[xX])?0*44048/
due to an editing error, was originally keyed assuming this was talking about the second level of lookup, which disagreed with the question
Question 4 (2 pt; mean 1.13) (see above)
Suppose that when looking up page table entries for the virtual adddresss 0x012 3456 789A:
the page table entry for the first-level was valid and contained physical page number 0x99,
the page table entry for the second-level was valid and contained physical page number 0xA4, and
the page table entry for the third-level was valid and contained physical page number 0xC3
Based on this information, when a program attempts to read data from virtual address
0x012 3456 789A, at what physical address will that data be found?
Write your answer as a hexadecimal number. If not
enough information is provided, write "unknown" and explain what information is missing in the comments.
Answer:
Key: /(?:0[xX])?0*[Cc]389[aA]/
Question 5 (2 pt; mean 1.34) (see above)
If this system had a 64-entry, 8-way TLB, that TLB would use 3 index bits. How many tag
bits would it use?